性能和可伸缩性
使用线程的目的之一是为了提升性能,但与此同时可能也带来其他问题(安全性,活跃性,额外的开销),不论如何,首先要保证程序能正常的运行,其后在确定使用一个“更好”的方案前,不要主观猜测,最好是用数据证实其“更好”。
对性能的思考
提升性能意味着什么?
用更少的资源做更多的事
资源:CPU周期(时间复杂度),内存(空间复杂度),文件/网络IO,数据库链接等等
性能与可伸缩性
性能衡量的指标?
服务时间、延迟时间、吞吐率、效率、可伸缩性以及容量等
没有对比就没有伤害
可伸缩性是什么意思?
意思是增加资源时,无其他修改即可能带来性能的提升。
可伸缩性的优化和传统的性能优化的区别?
- 传统的性能优化:以更小的代价完成相同的工作(如使用缓存、使用nlogn算法代替n2算法)对比两个程序的性能,就是对比处理同样的工作,谁更快,谁消耗资源更少。
- 可伸缩性优化:计算并行化,从而能利用更多地计算资源来完成更多的工作。对比两个程序的可伸缩性,就是增加计算资源,谁相应的提升的更快。
传统的性能优化直接是“能力”的优化,可伸缩性是“潜力”的优化。前者在单线程中即可提现,后者最显著的提升就是使用多线程。
评估各种性能的权衡因素
没有最好的优化方案,只有最合适的优化方案:
是否真的有所提升?测试数据说话
Amdahl定律
通过程序中串行部分的占比,推算出增加资源对于性能的提升率(相比单线程)。
关于加速比和Amdahl定律,参考百度百科——加速比)
推导公式:Speedup <= 1 / (F + (1 - F) / N)
F是必须被串行执行的部分所占比例,
N是机器中含有处理器的个数
推论1:串行部分占比0(F=0)时,Speedup <= N,理想情况,性能随处理器个数提升
推论2:串行部分占比1(F=1)时,Speedup <= 1,处理器个数的提升无法带来性能的提升
推论3:处理器个数趋于无穷(N→∞),Speedup <= 1/F,当处理器达到足够的数量后,性能瓶颈是串行部分占比
图: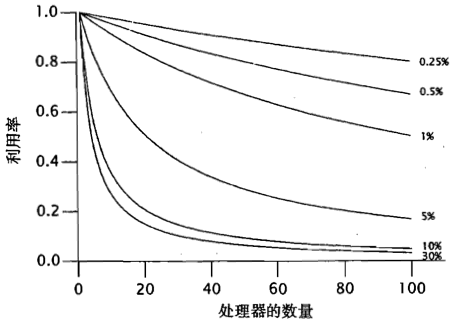
推论4:串行比分占比既是再低,对可伸缩性的影响也是巨大的。
并发程序中一定会有串行部分
Amdahl定律应用
利用Amdahl定律应用,取两组CPU数量,引入二元方程组,计算出串行部分占比,再利用Amdahl定律应用,推算出达到最大加速比的CPU数量
线程引入的开销
线程引入的开销有哪些?
山下文切换
上下文切换会有额外的非必要开销
过程:保存当前运行线程的执行上下文,并将新调度进来的线程的上下文设置为当前上下文
该过程操作系统,JVM,应用程序都会消耗CPU周期。首次调度,由于缓存缺失,耗时更多。
内存同步
为确保安全性,多线程间的协调时内存同步会有额外的开销。
原因:内存同步可见性需要特殊的指令保证,这个指令可能会导致刷新写缓存、使缓存失效、抑制重排序等优化等,这些都是额外开销
注意:当同步处理中并无数据竞争时,JVM会采取一些优化措施,这时开销可以忽略不计:
- 锁消除:分析当前对象是否只作用在栈中,消除无数据竞争的锁
- 锁合并:将近邻的锁合并,减少锁请求和锁释放的次数
阻塞
频繁的阻塞会增加上下文切换频繁,如果等待的时间很短,非必要的额外开销会大于本身业务的必要开销,这时候可以采取自旋的方式代替
如必要开销1秒,上下文切换带来的额外开销9秒,考虑只有两个线程,这时候使用阻塞锁第二个线程完成总共需要10秒,而使用自旋只需要2秒。(如果考虑)
减少锁的竞争
锁的竞争会导致串行比增加,同时也会增加线程上下文切换的开销。
有哪些降低竞争程度?
- 减少锁的持续时间
- 降低锁频率
- 代替独占锁
减少锁的持续时间
移出持有锁过程中耗时长但是无竞争的代码
减少锁粒度
锁分解:降低锁保护对象的范围
1 | //优化前 |
锁分段:对一组独立对象上的锁分解
1 | public Object get(Object key) { |
在ConcurrentHashMap中就采用了锁分段来实现
锁分解后如果会存在需要共享的数据,这些数据会成为热点域,竞争会很频繁,如例:HashMap.size()
应该避免热点域,可以分解热点域,如ConcurrentHashMap为每个分段都维护一个独立的size计数,并通过每个分段的锁来维护总size
代替独占锁
不适用独占锁,使用其他锁代替,如并发容器、读写锁、不可变对象、原子变量
监控CPU利用率
如果CPU利用率不高,可能原因:
- 负载不充足(系统没怎么用)
- IO密集
- 外部资源限制,如数据库连接
- 锁竞争
如果CPU利用率很高,并且总有可运行线程在等待,可以考虑增加处理器数量
注意,如果CPU持有内核占比较高,说明上下文切换频繁,这大概是由于阻塞导致
减少线程上下文切换的开销案例
案例:日志服务采用生产者——消费者来实现的好处是,将阻塞的IO放到一个日志线程中,避免多个任务线程由于IO阻塞,导致上下文切换频繁。

