虚拟内存
本章的核心内容:
- 虚拟内存是如何工作的
- 应用程序如何使用和管理虚拟内存
物理和虚拟寻址
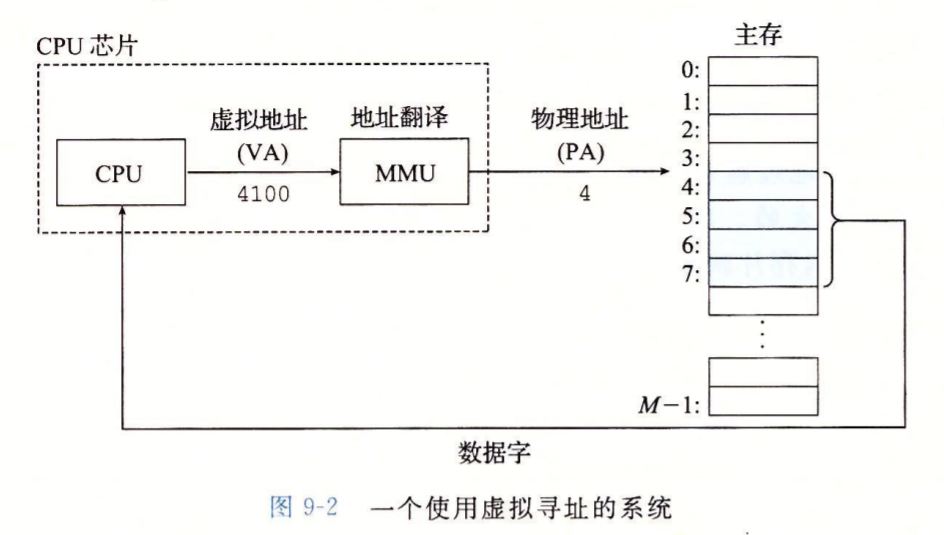
虚拟寻址的简单过程?
CPU中的内存管理单元(MMU)利用存放在主存中的查询表来动态翻译虚拟地址
地址空间
如何理解虚拟地址和物理地址的区别?
物理地址是实际的物理内存空间地址
虚拟地址是利用磁盘生成的逻辑内存空间
为什么需要引入虚拟内存的机制?
没有虚拟内存,程序员需要自己去管理物理地址,因此每次都需要人为地去计算和分配地址,这是一项复杂而且繁琐的工作。
虚拟内存的好处有:
- 让主存作为虚拟内存的缓存,更好的发挥稀缺的主存空间的作用
- 虚拟内存把内存的管理交给操作系统,不需要程序员去分配内存,提高了工作的效率和内存的安全。
- 固定的虚拟内存空间简化了程序的编译、链接、加载等等
缓存
什么是虚拟内存?
概念上来说,虚拟内存是一个存放在磁盘上N个连续字节大小的数组。
这个数组的内容被缓存在主存中
如何理解虚拟页的存在?
和其他缓存一样,数据被分割为块来作为传输单元
虚拟页中的块也被称为虚拟页(VP)
与之在主存上对应的叫物理页(PP)
虚拟内存的出现比缓存要早,所以这里延续传统,并没有使用虚拟块
虚拟页的三种不相交状态是?
- 未分配:虚拟内存中未分配(未使用,没有任何数据关联)的页
- 未缓存:虚拟内存中已分配的页
- 已缓存:缓存在主存的已分配虚拟空间
如何区分SRAM和DRAM?
为了区分不同的缓存
- SRAM:L1,L2,L3高速缓存
- DRAM:虚拟内存的缓存——主存
DRAM为什么不命中处罚很大?
DRAM比SRAM慢10倍
读写磁盘要比DRAM慢大约100000多倍
DRAM为了减少不命中处罚的手段?
- 采用较大的块(虚拟页)
- DRAM采用全相联的方式(没有组之间的区别)
- 采用更复杂精密的替换算法
- DRAM总是采用写回的方式
如何管理虚拟内存在DRAM中的缓存(是否命中,地址转换,替换策略)?
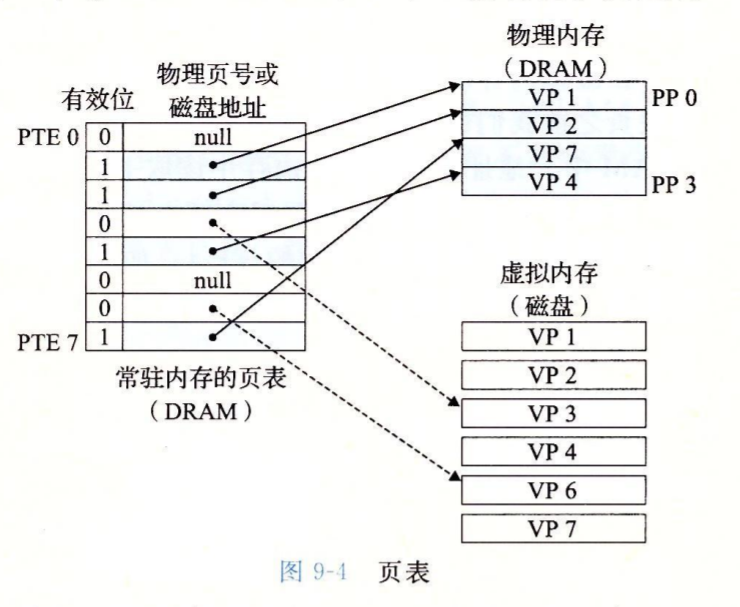
使用页表进行管理
页表是虚拟页和物理页的一个映射关系,除此还可以维护页的其他属性。
虚拟页的每一页都对应页表中的一个条目(PTE)
条目与虚拟页三种状态的对应?
- 有效位为1:已缓存
- 有效位为0,空地址:表示未分配页
- 有效位为0,有数据:表示未缓存
如何处理命中、缺页?
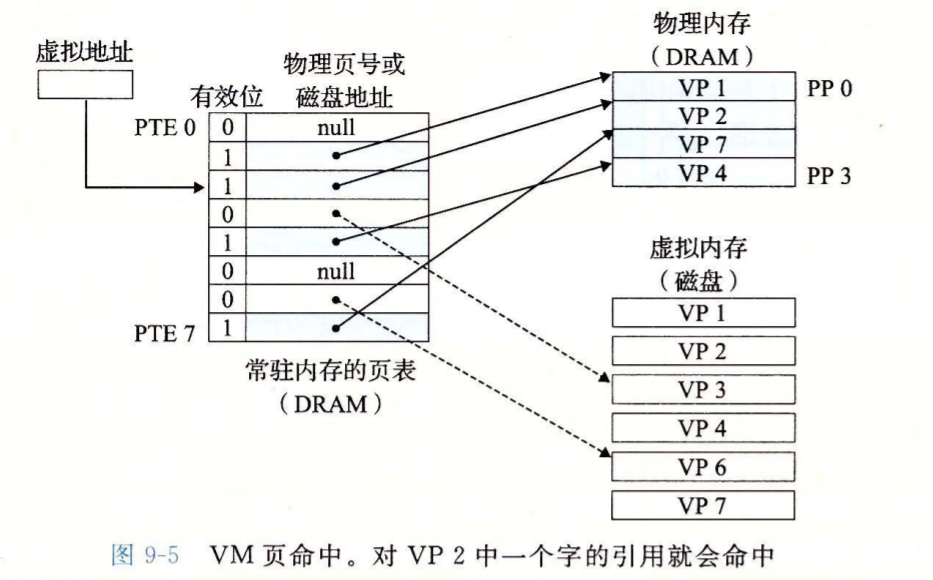
命中未缓存的表条目叫做缺页
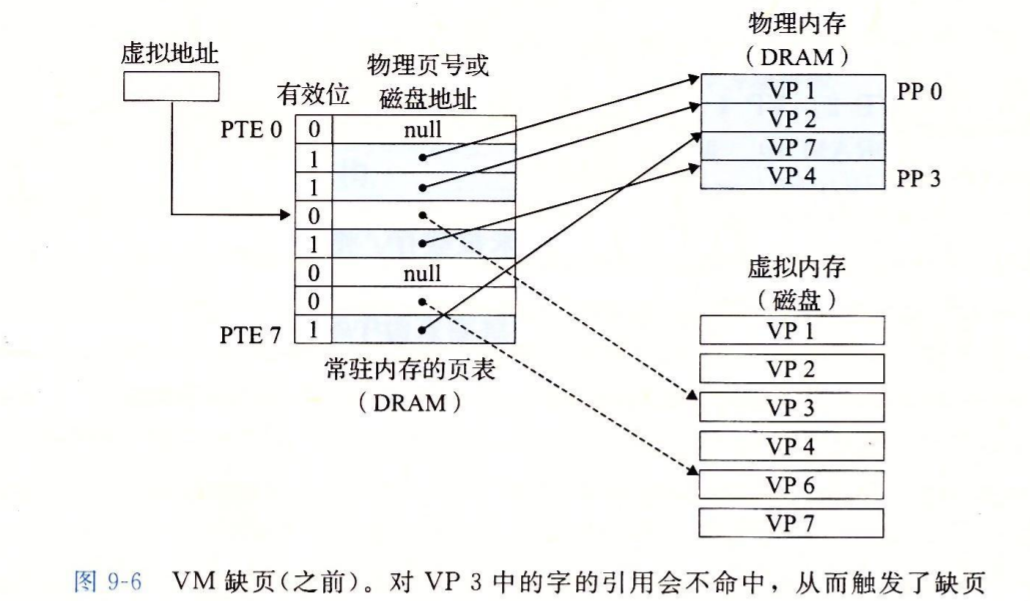
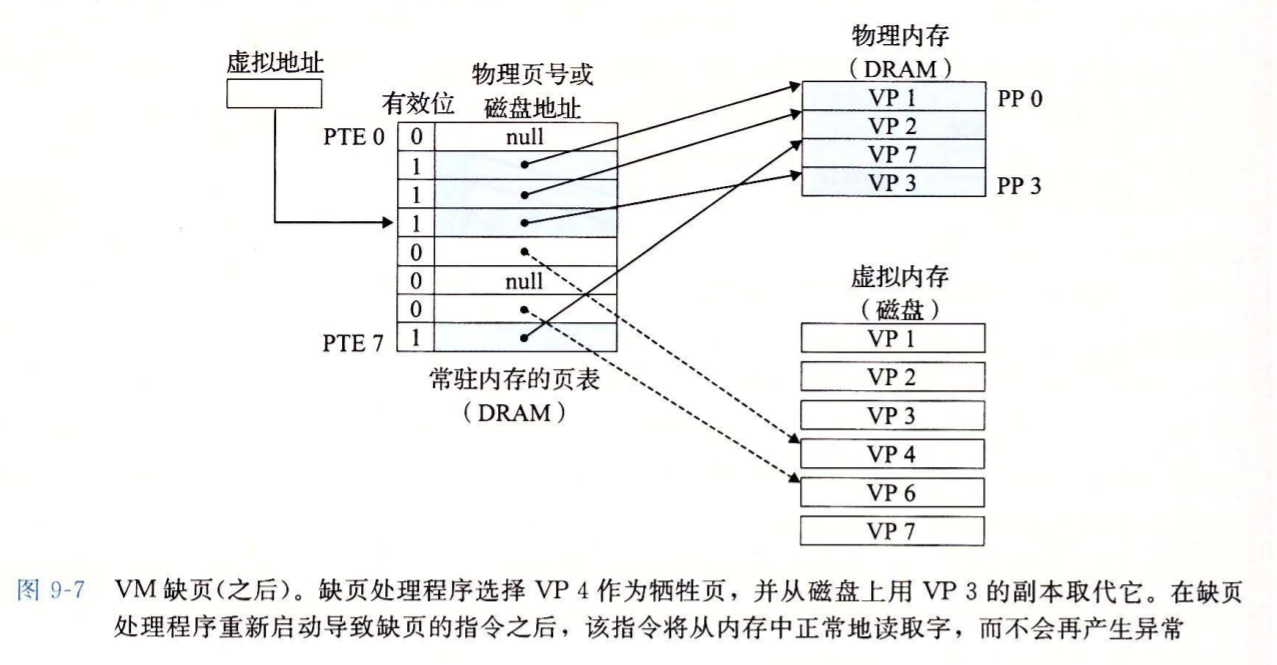
为什么虚拟内存需要读写磁盘,性能反而更好?
良好的局部性是缓存良好工作的唯一保证
内存管理
虚拟页如何简化了内存的管理?
- 简化链接:独立的内存空间简化了链接器的设计和实现,固定的内存格式(如代码段总是从虚拟地址0x400000开始),把实际物理地址的分配问题交给底层,专注于链接的算法。链接完成时即可确定部分静态的内存地址
- 简化加载:更容易加载可执行文件和共享对象文件,只需要分配目标文件中固定的节即可
- 简化内存分配: 用户不需要通过实际的物理内存去计算空闲内存,让这些都交给操作系统去实现
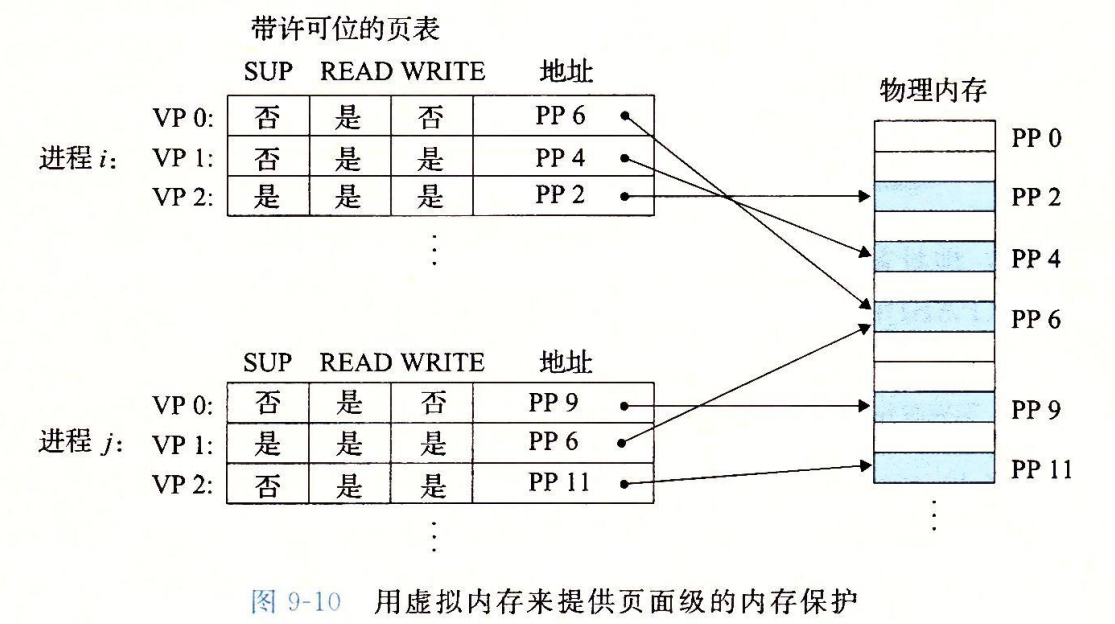
内存保护
如何进行内存的保护?
PTE中有3个权限字段,控制读、写和访问
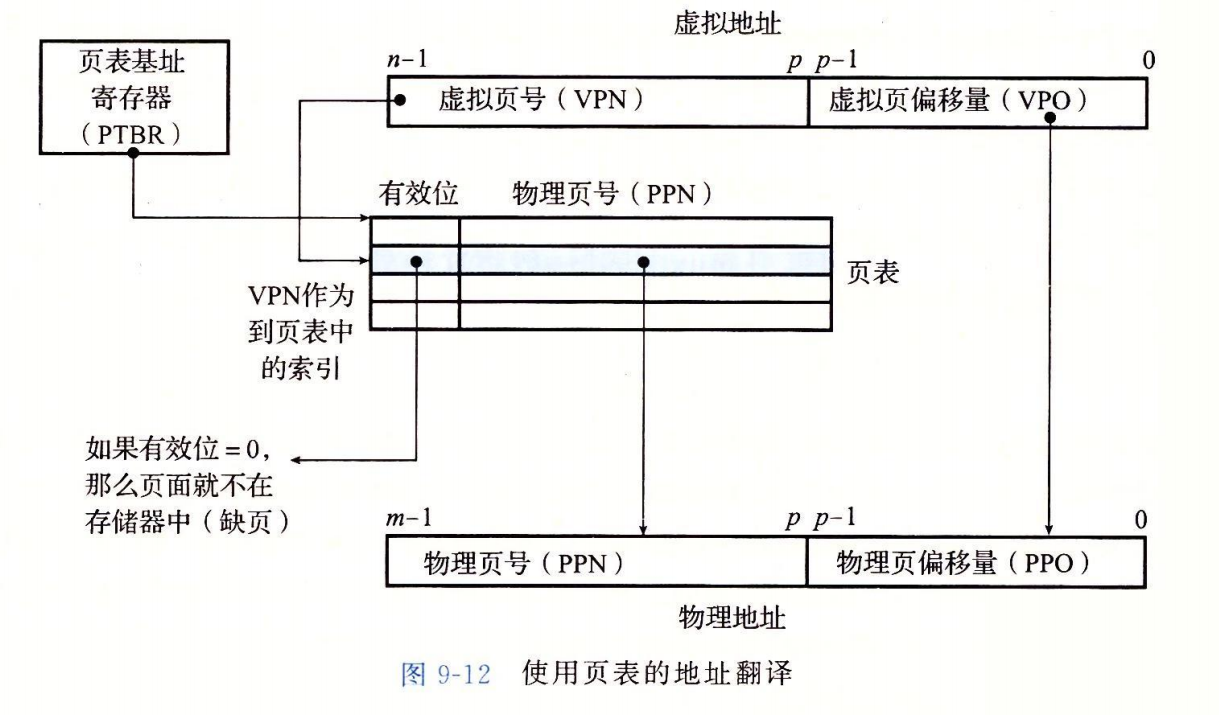
地址翻译
如何从虚拟地址转换成物理地址?
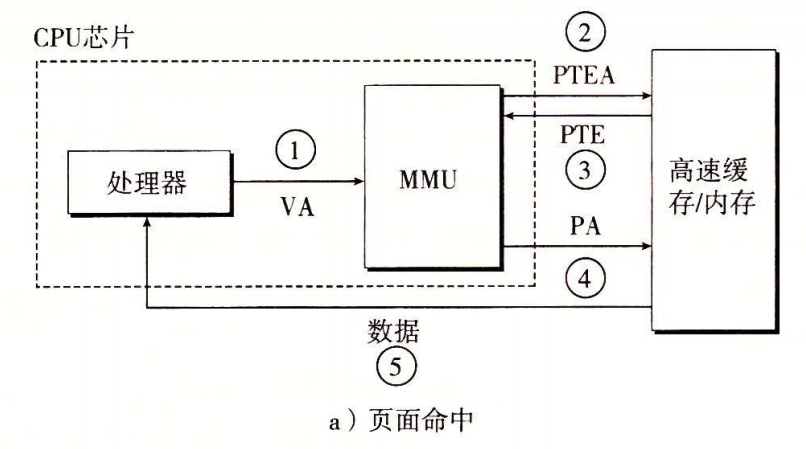
页面命中时如何转换?
缺页时如何转换?
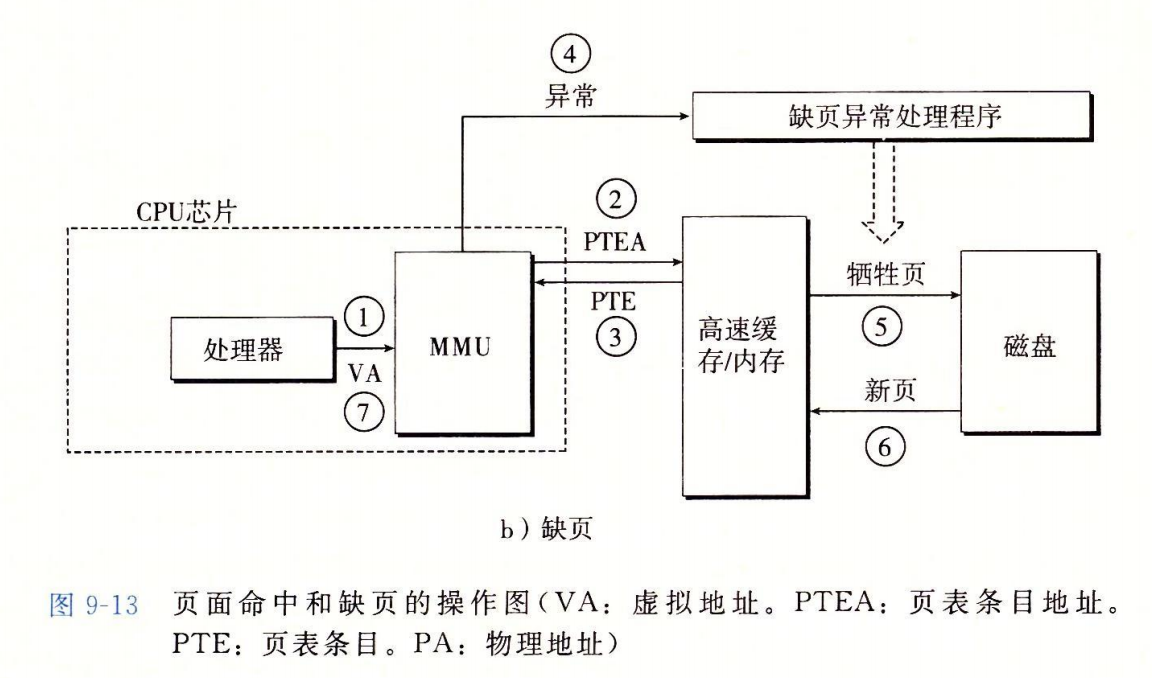
地址转换如何和高速缓存结合?
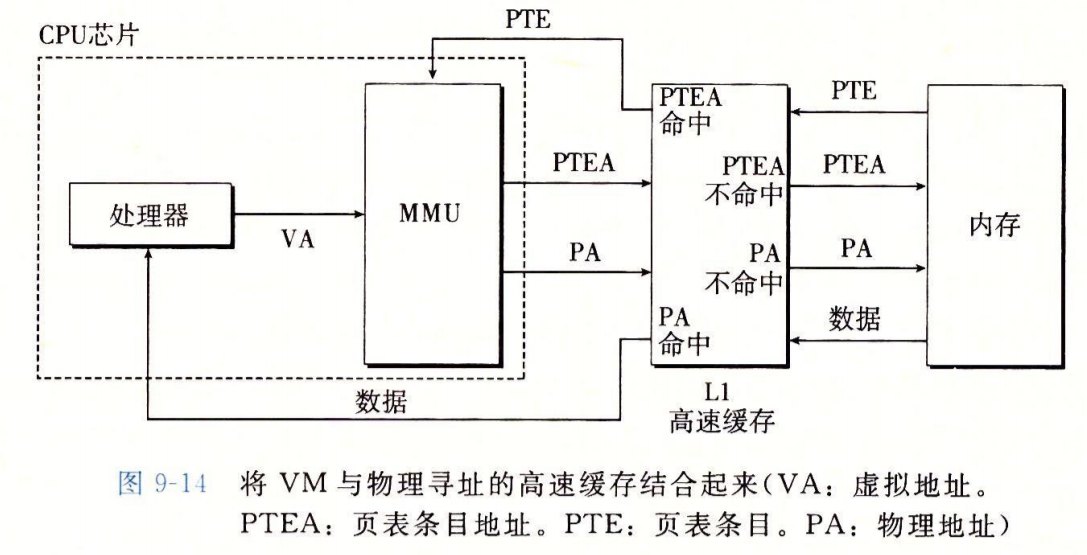
如何进一步减小地址转换的开销?
在MMU中建立一个PTE的缓存,称为翻译后备缓存器(TLB)
和一般的缓存一样,采用组相联的方式
使用VPN进行索引

如何減少页表占用的内存空间?
一个32位的虚拟空间,4KB的页大小,4字节的PTE
那么每个进程都需要一个4MB的页表
这样下去内存还是吃不消
常见的压缩方式是采用层次结构的页表
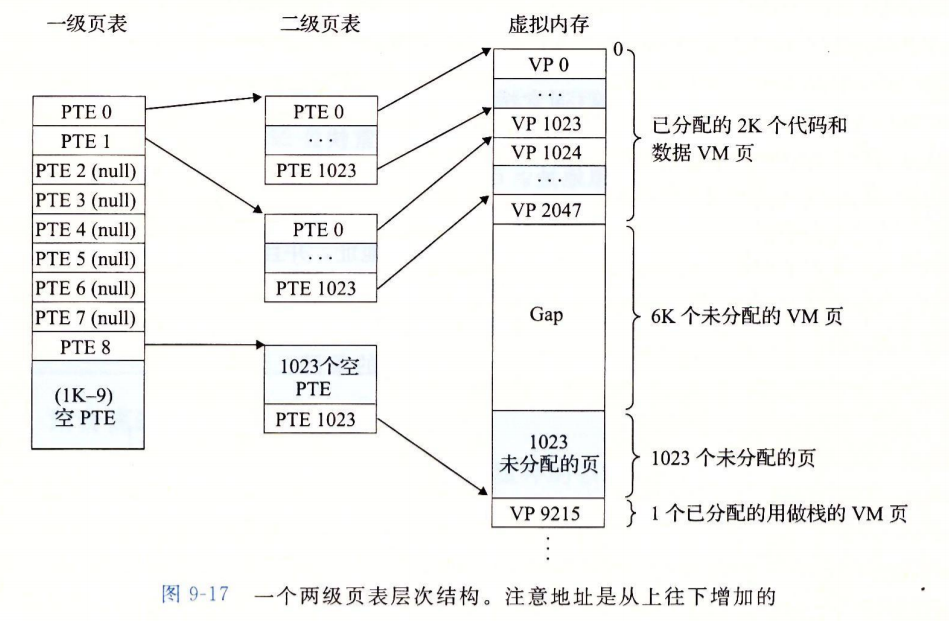
- 如果上级页表中的PTE是空的,那么相应的二级页表就不存在
- 只有一级页表才总需要在主存中,其他级页表按需调入调出
多级页表如何寻址?
MMU必须访问多个PTE
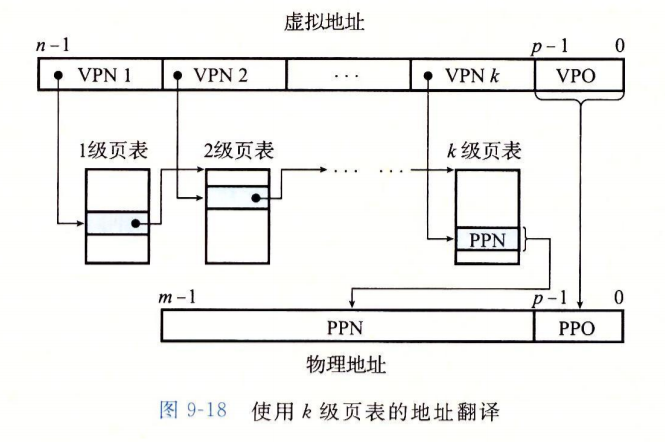
这种空间的压缩导致了更多次的内存访问,需要付出多少的时间代价?
由于不同层次的PTE都可以在TLB中缓存
所以多级页表的地址翻译并不会比单级页表慢很多
综合:案例分析
实际案例研究——运行linux的intel core i7
core i7的地址翻译?
Linux的虚拟内存结构?
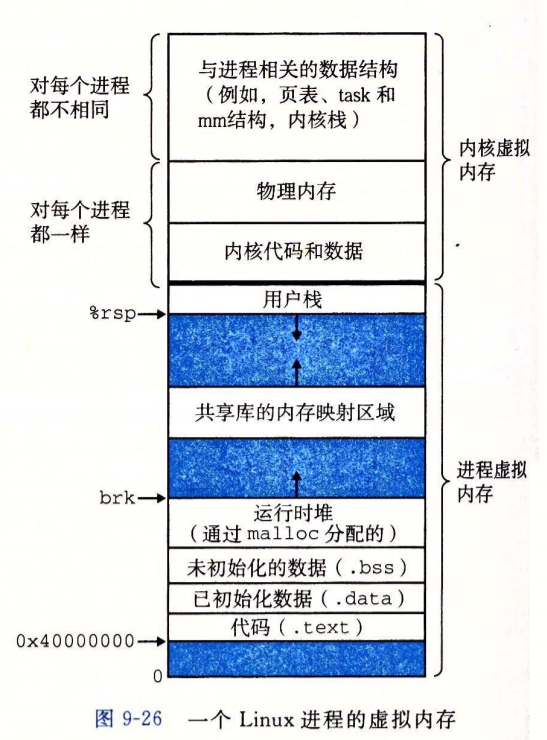
Linux如何组织虚拟内存?
Linux使用区域(段)来组织虚拟内存
Linux为每个进程都维护这一个任务结构(task_struct源码)
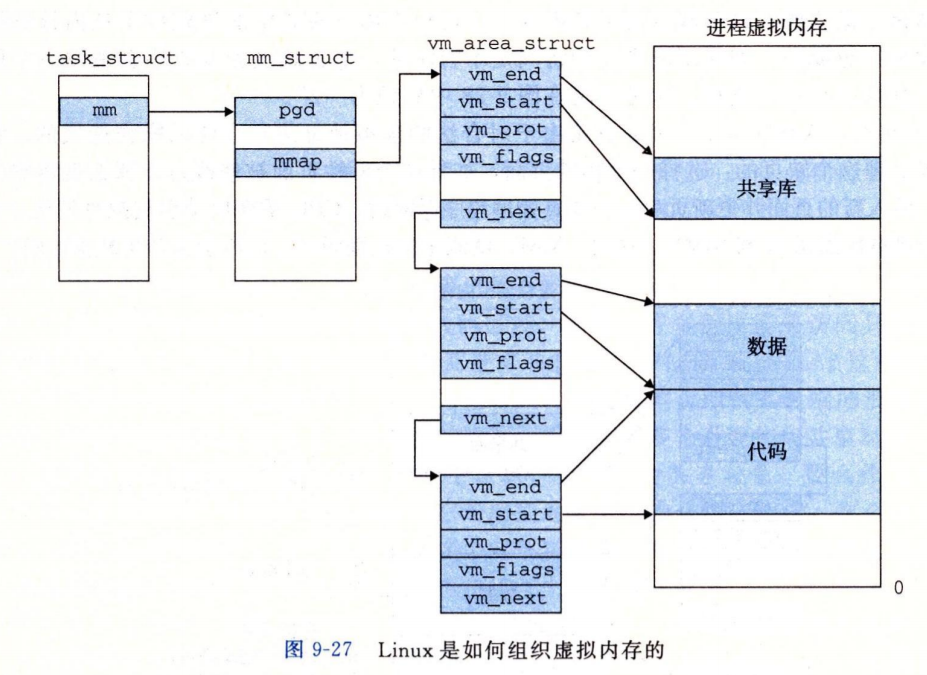
Linux在进程的上下文中维护
Linux中使用区域组织虚拟内存的意义?
- 将功能相同的虚拟页组织起来
- 允许虚拟地址空间有空隙,不需要去记录不存在数据的虚拟页
- 记录了每个区域的权限
Linux中如何处理缺页?
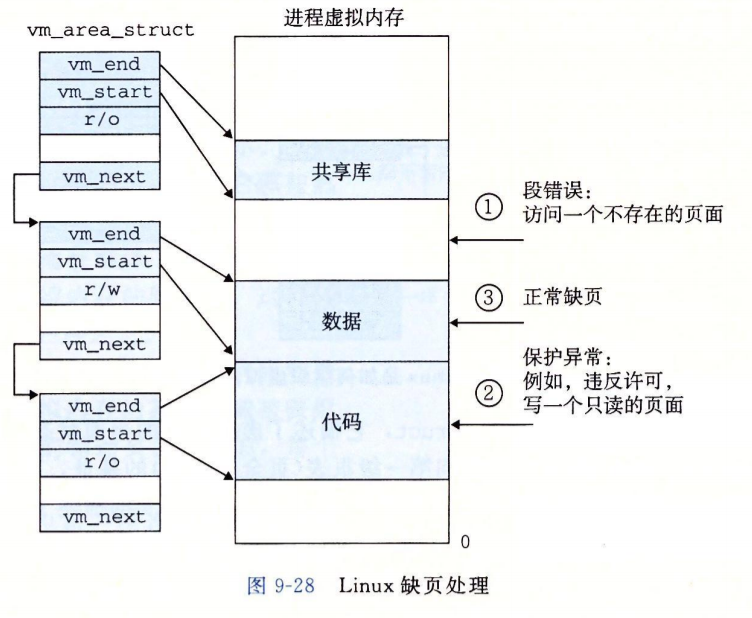
内存映射
什么是内存映射?
将一个虚拟内存区域和磁盘上的对象关联起来,以初始化虚拟内存区域的内容,这个过程就叫内存映射
可以简单的理解为初始化虚拟内存
哪些硬盘对象可以进行内存映射?
- 普通文件对象(包括之前说的可执行文件),按需调度(发生缺页时才放到物理内存中)
- 匿名文件:由内核创建,当引用到匿名文件的虚拟页时,只会用二进制零覆盖牺牲页(如果牺牲页有修改,则换出),然后更新页表,不会有实际的数据传输,所以也叫请求二进制零的页。
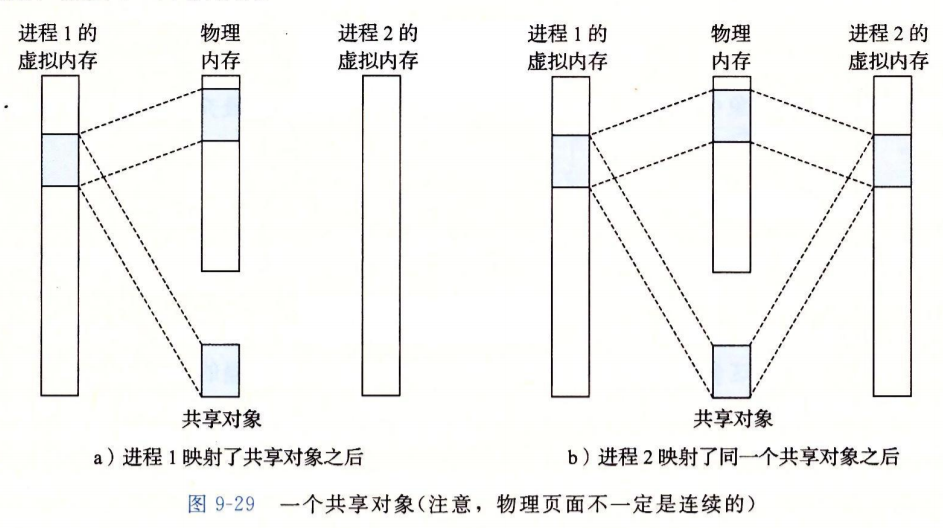
如何管理共享对象的虚拟内存?
如何管理私有对象的虚拟内存?
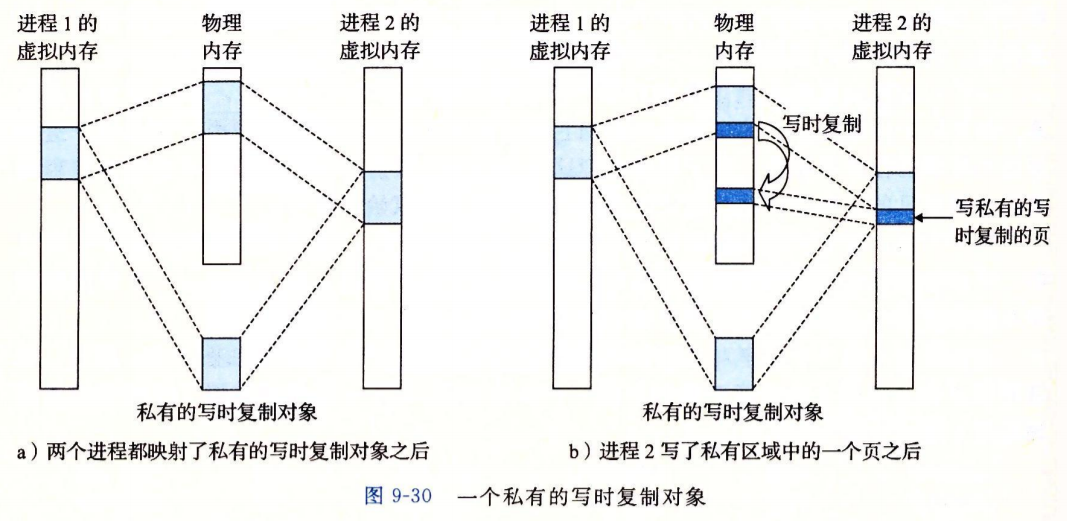
fork函数如何管理虚拟内存?
fork之后,拷贝原进程的虚拟空间,并将两个进程的虚拟页都设置为只读,写时复制
execve函数如何管理虚拟内存?
- 删除已经在的用户区域
- 映射私有区域(新程序的代码、数据、bss和栈区域)
- 映射共享区域
- 设置程序计数器(PC):指向代码区域的入口点
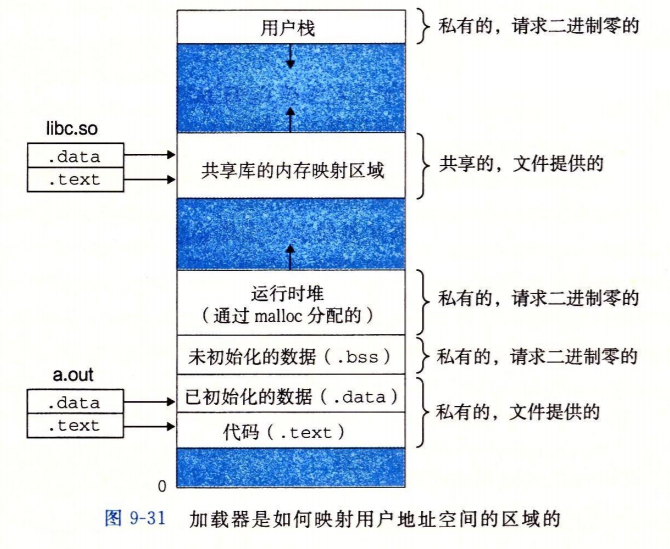
用户级内存映射:
1 | /** |
动态内存分配
什么是动态内存分配器?
动态内存分配器维护一个进程的虚拟内存区域,称为堆
堆中分为不同大小的块来进行管理
有已分配和空闲两种状态
为什么要使用动态分配?
使用动态内存分配管理堆更方便,也有更好的可移植性。
分配器有两种风格:
- 显式分配器:要求应用显式的释放已分配块
- 隐式分配器:分配器检查无用块并释放
相关细节:
- mallco要求的内存过大,返回null并设置errno
- mallco不初始化,初始化调用calloc
- 重新分配调用realloc
动态内存分配的要求和目标?
要求:
- 分配请求必须有相应的释放请求
- 分配请求需要立即执行,不允许重新排列或者缓存
- 只操作堆空间
- 对齐块
- 不允许修改已分配块
目标:
- 单位时间内完成的请求数尽可能多
- 堆的利用率尽可能大(已分配块的有效负载占比尽可能多)
什么是外部碎片和内部碎片?
- 内部碎片:已分配块大小和有效负载大小之差
- 外部碎片:分散的空闲块
实现动态分配器需要考虑哪些问题?
- 空闲块组织:我们如何记录空闲块?
- 放置:我们如何选择一个合适的空闲块来放置一个新分配的块?
- 分割:在我们将一个新分配的块放置到某个空闲块之后,我们如何处理这个空闲块中的剩余部分?
- 合并:我们如何处理一个刚刚被释放的块?
如何记录空闲块?
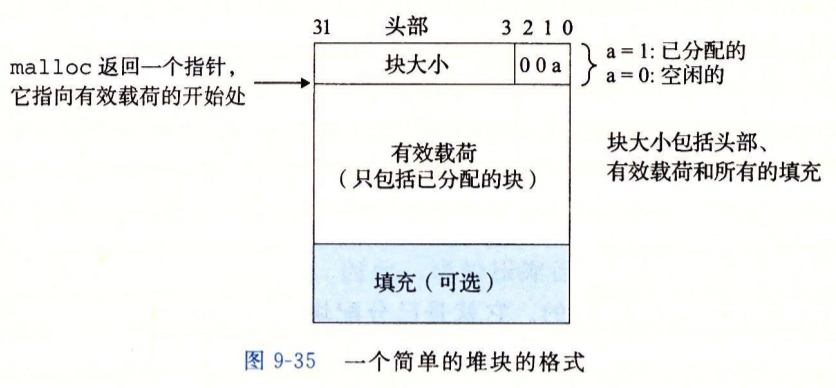
- 一个块由字的头部、有效载荷以及可能的额外的填充组成。
- 头部编码了这个块的大小(包括头部和所有的填充)以及该块的状态(已分配或者空闲的)。
- 上图显示的是该块强加了一个双子的对齐约束条件(一个字为2B),该块的大小就总是8的倍数,则块大小的最低3位总是0。
- 这里的填充有两个原因:
- 分配器的策略,用于对抗外部碎片。
- 满足对齐要求。
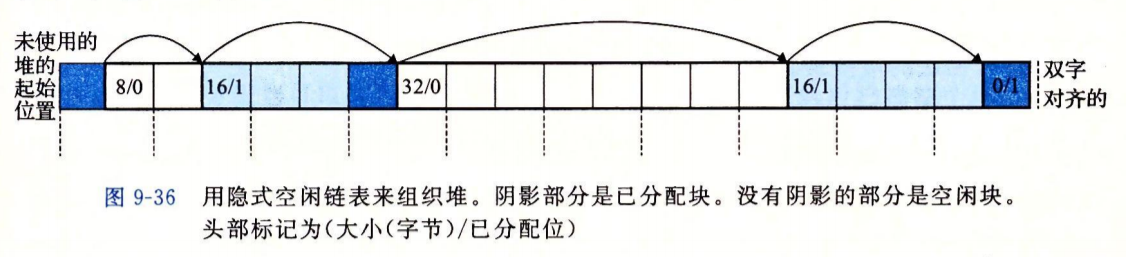
- 空闲块是通过头部中的大小字段隐含地连接着的。
- 后面的已分配但是大小为0的头部做为隐式链表的结尾标志。
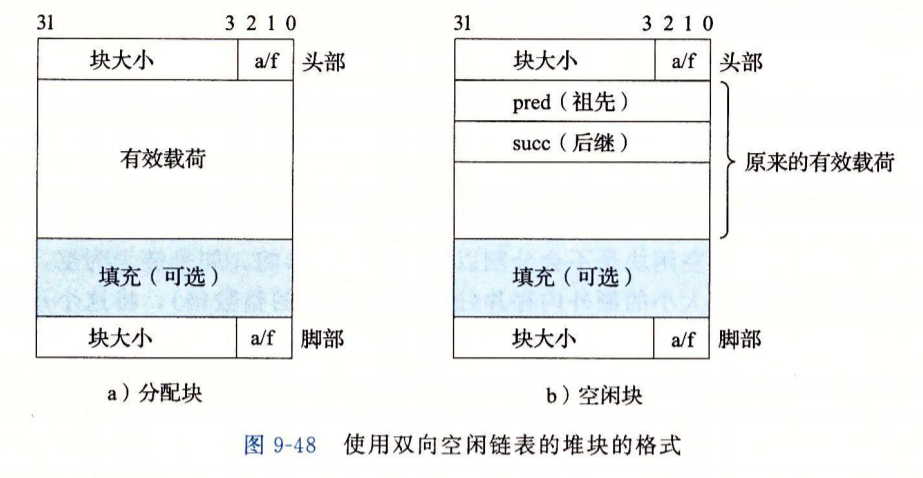
每个空闲块中,都包含一个前驱和后继指针
如何放置新的请求块?
放置策略:
- 首次适配:从头开始搜索空间链表,选择第一个合适的空闲块。
- 下一次适配:和首次适配很相识,只不过不是链表开始出开始每次搜索,而是从上一次查询结束的地方开始。
- 最佳适配:搜索每一个空闲块,选择合适所需请求大小的最小空闲块。
优点:
- 首次优点:将大的空间块保留在列表的后面,缺点:靠近列表起始处留下空闲块的碎片,增加了对较大块的搜索时间。
- 下次:knuth提出,比首次运行快一些,尤其是列表前面布满许多小的碎片时,然而下次比首次利用率要低得多。
- 最佳:利用率最高,但由于对堆的彻底的搜索,时间复杂度高;
如何分割空闲块?
一旦分割器找到一个匹配的空闲块,他就必须做另一个决定,那就是分配这个 空闲块中多少空间,一个是选择整个空间,简单快捷,但缺点是内部碎片,如果放置策略趋于产生好的匹配,额外的内部碎片可以接受;
然而,如果匹配的不太好,那么分配器通常会选择讲这个空间块分割为两个部分,一个部分为分配块,另外变成一个空的空闲块。
如果分配器不能为请求找到合适的空闲块将发生什么?
为了解决假碎片的问题,任何实际的分配器都必须合并相邻的空闲块,这个过程叫做合并,这就出现一个重要策略决定,也就是在每次一个块释放时,就合并所有的空闲块?还是推迟合并,知道某个请求分配失败,然后再去扫描整个堆,合并所有空闲块。
合并后的内存块也不够用怎么办?
然而这样还是不能得到足够大的块,分配器就会想内核请求额外的堆空间。
垃圾收集
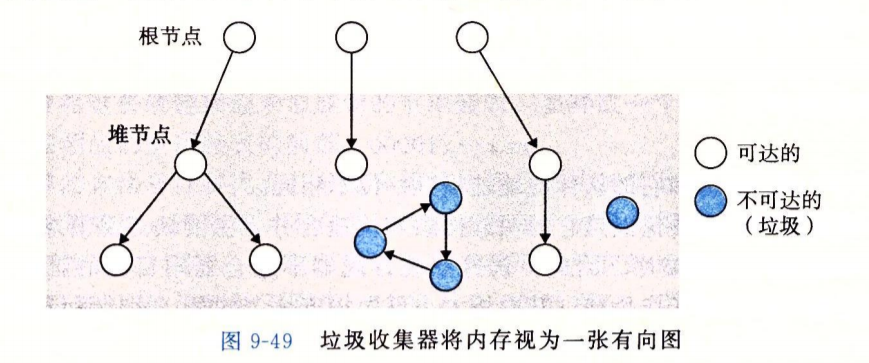
- 堆节点:已分配块
- 根节点:寄存器中的变量、栈中的变量、虚拟内存读写区域的全局变量
分配的内存未回收会有什么影响?
内存将不够
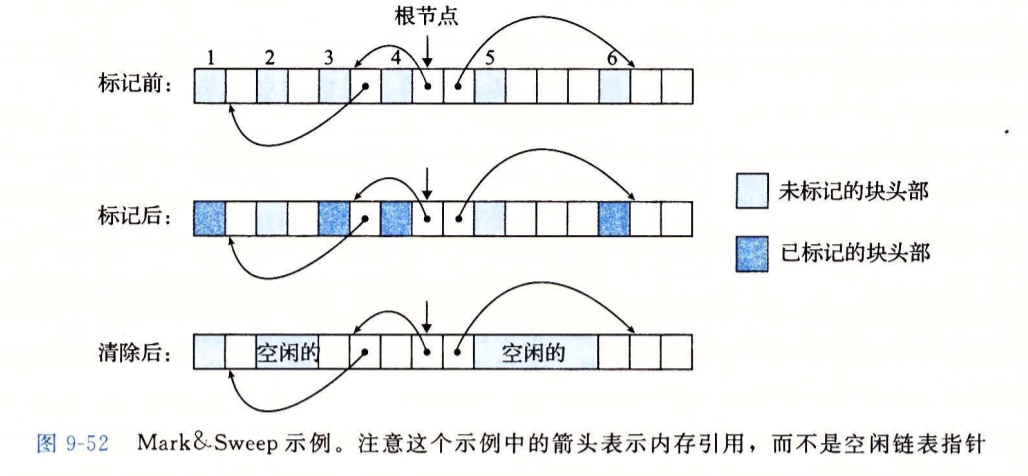
简要描述标记&清理回收算法?


C中的标记&回收算法有什么难题?
C无法区别是指针还是一个常量

