String
不可变
String中每一个看似会修改String的方法,其实都是创建了一个全新的对象。
这也比较符合常识。
不变带来的问题?
看下面的一个案例:1
2String a = "a";
String b =a + "abc" + 123 + "a";
String的“+”操作符使用append()重载了,append返回的是一个新对象。
a+”abc”会生成一个新的中间对象。
之后+123又生成一个中间对象,类推。
这样造成的问题是String的操作会生成许多没用的中间对象
怎么办?
JAVA的开发者也意识到这个问题。
于是最开始是对编译器作了一个优化。
像上面的案例,编译器会暗自生成一个StringBuilder来作字符串的拼接。
StringBuilder的append方法返回的是同一个对象。
优化过了我们就可以随意使用String了吗?
编译器的优化只针对String的简单操作。
涉及到String的循环拼接,每一个循环都要创建一个StringBuilder,这样实际的效果也没有多大的差别。
无意识的递归
当一个字符串对象+一个其他对象,会首先调用这个对象的toString()方法把它转成一个字符串对象。
格式化输出
还记得C中的printf()吗?
1 | printf("Row 1: [%d %f]\n", x, y); |
JAVA也延续了这种传统,使用System.out.printf()或者System.out.format():1
System.out.printf("Row 1: [%d %f]\n", x, y);
System.out.print()的真实面目:
底层使用了Formatter类,这个类是专门用来处理格式化的。
它有很多构造器,参数都是关于格式化结果输出到哪个地方:1
2Formatter f = new Formatter(System.out);
f.format("%s The Turtle is at (%d,%d)\n", name, x, y);
如何更精确的控制输出的格式?
正确的使用格式化说明符:1
%[argument_index$][flags][width][.precision]conversion
width:占位长度,不够用空格补。
.precision:多含义,最大长度,小数点个数。
+”-“:左对齐,默认是右对齐。
还记得C中的sprintf()吗?
1 | sprintf(s, "%d", 123); |
JAVA也延续了这种传统:1
String s = String.format("%02X ", b);
正则表达式
关于正则表达式的语法,百度一下吧。
注意的是JAVA中字符串里的“\”表示反斜杠,正则表达式中”\“表示一个反斜杠
因此在JAVA的字符串中的正则表达式里”\\”才表达表示反斜杠
如何创建正则表达式
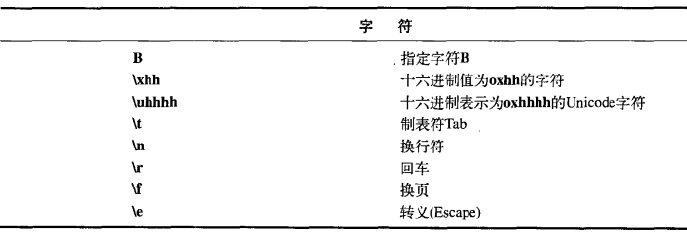

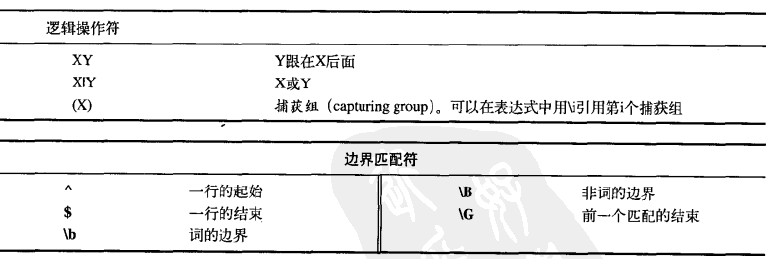
量词
- 贪婪型:它的特性是一次性地读入整个字符串,如果不匹配就吐掉最右边的一个字符再匹配,直到找到匹配的字符串或字符串的长度为0为止。它的宗旨是读尽可能多的字符,所以当读到第一个匹配时就立刻返回。
- 勉强型:它的特性是从字符串的左边开始,试图不读入字符串中的字符进行匹配,失败,则多读一个字符,再匹配,如此循环,当找到一个匹配时会返回该匹配的字符串,然后再次进行匹配直到字符串结束。
- 占有型:它和贪婪模式很相似,不同点是它不会往会吐。
JAVA里如何使用正则表达式?
最简答的是使用String中的一些方法:
- matches(“xxx”):成功true,失败false.
- split(“xxx”):以xxx来分割字符串为数组。
- replaceFirst(“xxx”,str),replaceAll:用str来替换匹配成功的值。
仅仅在String中使用正则表达式的功能还是有些简单的,有更多的用法?
Pattern和Matcher类
Pattern是一个正则表达式类,它的构造器私有化了,但是可以通过compile(string regex)返回一个正则表达式对象。
之后pattern里有个matcher(CharSquence str)来生成一个Matcher对象。
CharSquence是String,StringBuilder,CharBuffer,StringBuffer抽象出来的一般化定义。
Matcher对象里提供了更多匹配的功能:
- matches():整个字符串整个匹配。
- lookingAt():起始部分是否匹配。
- find():迭代式的搜索是否有匹配的部分,接受一个起始点参数I。
如何从匹配出来的字符串中选取我需要的内容?
使用组,组是用括号划分的正则表达式:A(B(C))D
组0是ABCD,组1是BC,组2是C。
案例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public class Groups {
static public final String POEM = "Twas brillig, and the slithy toves\n" + "Did gyre and gimble in the wabe.\n" + "All mimsy were the borogoves,\n" + "And the mome raths outgrabe.\n\n" + "Beware the Jabberwock, my son,\n" + "The jaws that bite, the claws that catch.\n" + "Beware the Jubjub bird, and shun\n" + "The frumious Bandersnatch.";
public static void main(String[] args) {
Matcher m = Pattern.compile("(?m)(\\S+)\\s+((\\S+)\\s+(\\S+))$").matcher(POEM);
while (m.find()) {
for (int j = 0; j <= m.groupCount(); j++) printnb("[" + m.group(j) + "]");
print();
}
}
}
/*
Output: [the slithy toves][the][slithy toves][slithy][toves]
[in the wabe.][in][the wabe.][the][wabe.]
[were the borogoves,][were][the borogoves,][the][borogoves,]
[mome raths outgrabe.][mome][raths outgrabe.][raths][outgrabe.]
[Jabberwock, my son,][Jabberwock,][my son,][my][son,]
[claws that catch.][claws][that catch.][that][catch.]
[bird, and shun][bird,][and shun][and][shun]
[The frumious Bandersnatch.][The][frumious Bandersnatch.][frumious][Bandersnatch.]
*///:~
- start():返回匹配成功的字符串的开始位置。
- end():返回匹配成功的字符串的最后位置+1。
- Pattern.split(CharSequence input[,int limit]):断开成字符串对象数组。
- reset():将现有的Matcher用于一个新的字符串,好处是不需要创建很多个Matcher对象。
正则表达式结合I/O流可以实现对文件的检索。
至于如何读取文件,在以后会详细的学习。

