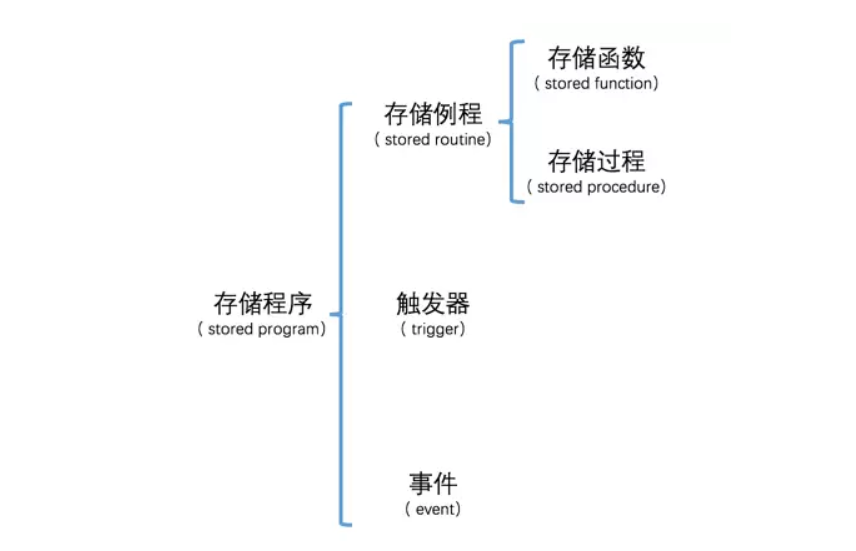
存储程序
结构:
自定义变量
MySQL中有变量吗?
MySQL中的变量关键词是@
- 常量赋值:SET @a = 1 or SET @a=”abc”
- 变量赋值:SET @a = @b
- sql语句赋值:SET @a = (SELECT..) (要求sql语句的返回结果只有一个)
- sql语句赋值除了使用SET 和 “=”,还可以使用INTO,如(SELECT..) INTO @a,使用INTO可以一次赋多个值。
- 查询变量:SELECT @a
修改语句执行终结符
什么是语句执行终结符?
在MySQL的命令行窗体里,命令如果遇到了”;”就会执行,并且转到下一行重新输入。
为了同时输入多行语句,需要修改语句终结符。
如何修改?
默认执行的终结符是”;”
使用delimiter来修改
案例:
1 | delimiter EOF |
存储函数
什么是存储函数
将sql语句写在一个函数中执行
如何创建一个存储函数
1 | CREATE FUNCTION 存储函数名称([参数列表]) |
需要指定函数名称、参数列表、返回值类型以及函数体内容
在哪些地方可以调用存储函数?
函数调用可以作为
- 查询对象
- 搜索条件
- 和别的操作数一起组成更复杂的表达式
如何查看或删除MySQL中已存在的存储函数?
查看系统mysql中的存储函数:
- 模糊查询:SHOW FUNCTION STATUS [LIKE 需要匹配的函数名]
- 精确查询:SHOW CREATE FUNCTION 函数名
删除存储函数:DROP FUNCTION 函数名
如何在存储函数中定义变量?
语句:DECLARE 变量名 数据类型 [DEFAULT 默认值]
函数体中的变量名不允许加@前缀
判断语句的编写:
1 | IF 布尔表达式 THEN |
循环语句的编写:
WHILE循环
1
2
3WHILE 布尔表达式 DO
循环语句
END WHILE;REPEAT循环
1
2
3REPEAT
循环语句
UNTIL 布尔表达式 END REPEAT;LOOP循环
1
2
3
4循环标记:LOOP
循环语句
LEAVE 循环标记;
END LOOP 循环标记;
注释:
- 使用”–”
存储过程
什么是存储过程?
存储函数侧重于执行这些语句并返回一个值,而存储过程更侧重于单纯的去执行这些语句。
如何创建存储过程?
1 | CREATE PROCEDURE 存储过程名称([参数列表]) |
调用:
1 | CALL 存储过程([参数列表]); |
存储过程在执行中产生的所有结果集,全部将会被显示到客户端。
关于存储过程的参数,需要注意的是:
与存储函数不一样的是,存储过程可以指定参数类型,注意参数类型和数据类型是不一样的。1
参数类型 参数名 数据类型
参数类型有3钟:
- IN-只读取参数,对在过程中对参数的重新复制并不会改变在过程调出之后的结果。。
- OUT-只修改参数,OUT参数类型的变量只能用于赋值,对类型的变量赋值是会被调用者看到的。
- INOUT-上述两个的结合
如果不指明,默认是IN,因此,在存储函数中的参数类型只能是IN
查看和删除存储过程:
查看系统mysql中的存储过程:
- 模糊查询:SHOW PROCEDURE STATUS [LIKE 需要匹配的函过程名]
- 精确查询:SHOW CREATE PROCEDURE 过程名
删除存储函数:DROP PROCEDURE 过程名
在存储函数中的语法都可以使用到哦存储过程中
存储函数和存储过程的区别在哪?
- 存储函数需要指明返回,存储过程不需要。
- 参数类型不一样。
- 存储函数只能返回一个值,存储过程可以通过OUT来返回多个值。
- 存储函数的函数体的执行不会显示到客户端,存储过程的会。
- 调用的方式不同。
游标
游标是什么?
给变量赋值我们之前学过使用SET 和 “=” 给 “@”变量直接赋值,和使用INTO来赋值
但是这样结合SQL语句时要求每一列的返回只有一个值,这样很不灵活。
为了解决这个问题,mysql提供了“游标”,这个概念类似JAVA中的迭代器,可以一次性赋多个值。
如何创建一个游标?
DECLARE 游标名称 CURSOR FOR 查询语句;
游标指向查询结果的第一行
案例:
1 | delimiter $ |
游标需要指定打开和关闭:
OPEN 游标名称;
CLOSE 游标名称;
案例:
1 | delimiter $ |
游标怎么使用?
FETCH 游标名 INTO 变量1, 变量2, … 变量n
将一行中的每一列赋值到对应的变量中
案例:
1 | delimiter $ |
现在只能取出一条
游标在使用“FETCH”之后自动转向下一行,没有下一行的时候指向NULL。
那么当FETCH判断当前为NULL的时候,后面的语句还会执行吗?
有下面两种语法:
DECLARE CONTINUE HANDLER FOR NOT FOUND 可执行语句;
DECLARE EXIT HANDLER FOR NOT FOUND 可执行语句;
这个语句的含义是使用“FETCH”时,如果检查到当前游标指向是null,则执行后面的语句。
上面两个的区别类似JAVA中的continue和break
案例1:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23CREATE PROCEDURE cursor_demo()
BEGIN
-- 声明变量
DECLARE m_value INT;
DECLARE n_value CHAR(1);
DECLARE not_done INT DEFAULT 1;
-- 声明游标
DECLARE t1_record_cursor CURSOR FOR SELECT m1, n1 FROM t1;
-- 在游标遍历完记录的时候将变量 not_done 的值设置为 0,并且继续执行后边的语句
DECLARE CONTINUE HANDLER FOR NOT FOUND SET not_done = 0;
-- 使用游标遍历
OPEN t1_record_cursor;
WHILE not_done = 1 DO
FETCH t1_record_cursor INTO m_value, n_value;
SELECT m_value, n_value, not_done;
END WHILE;
CLOSE t1_record_cursor;
END
结果:
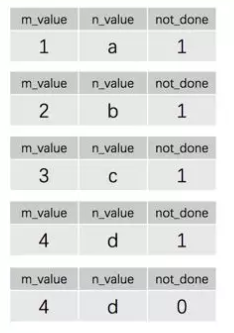
分析一下:使用CONTINUE的方式,最后一行会执行两次,为什么?
案例2:
1 | CREATE PROCEDURE cursor_demo() |
触发器
什么是触发器?
在执行插入,更新,删除操作之前或者之后执行其它操作(比如校验数据)
创建触发器:
1 | CREATE TRIGGER 触发器名 |
EACH ROW表示
- INSERT:表示新插入的数据。
- DELETE:表示将要删除的那些数据。
- UPDATE:表示将要更新的那些数据。
如何操作还没有记录到数据库中的数据呢?
- OLD:操作记录之前的旧数据(对于INSERT而言不存在)
- NEW:操作记录之前的新数据(对于DELETE而言不存在)
BEFORE和AFTER之间的区别到底是什么呢?
理解的一个点在于当需要操作的数据记录到数据库中之后就不允许做修改。
一般需要更改要操作的数据时使用before。如果记录日志要使用after。
注意:
- 触发器中不能有输出结果
删除和查看触发器:
- 查看当前数据库的触发器:SHOW TRIGGERS;
- 查看具体的触发器定义:SHOW CREATE TRIGGER 触发器名;
- 删除触发器:DROP TRIGGER 触发器名;
事件
什么是事件?
指定一个事件或者某个周期指定一些操作称为事件。
创建事件:
1 | CREATE EVENT 事件名 |
- 事件点:
AT ‘2018-03-10 15:48:54’
AT DATE_ADD(NOW(), INTERVAL 2 DAY)–表示两天后 - 周期
EVERY 1 HOUR
EVERY 1 HOUR STARTS ‘2018-03-10 15:48:54’ ENDS ‘2018-03-12 15:48:54’
查看和删除事件?
- 查看所有事件:SHOW EVENTS;
- 查看具体事件的定义:SHOW CREATE EVENT 事件名;
- 删除事件:DROP EVENT 事件名;
事件需要手动启动:event_scheduler = ON

